Директивы и настройки файла Robots.txt: что нужно знать

- Почему индексация сайта зависит от файла robots.txt
- Какие бывают директивы и как их настраивать
- User-agent
- Disallow
- Allow
- Sitemap
- Clean-param
- Crawl-delay
- Правильная настройка robots.txt
- Как добавить robots.txt и где лежит файл
- Проверка синтаксиса
- Вывод
Для индексации сайта роботы поисковых систем определяют, к каким разделам у них есть доступ. Эти данные прописаны в текстовом файле robots.txt. Он работает в качестве преграды для поисковых алгоритмов и указывает, какие страницы могут смотреть роботы, а какие для них закрыты.
Глубину ограничений настраивают с помощью директив. Роботы воспринимают их как инструкции к действию. И если они видят команду Disallow с указанием разделов сайта, то не будут их индексировать. В этой статье расскажем, как настраивать директивы для Яндекса и Google и как составить правильный robots.txt.
Почему индексация сайта зависит от файла robots.txt
Если не хотите, чтобы частные и корпоративные данные попадали в поисковые системы, нужно закрыть к ним доступ. Поэтому в robots.txt стоит прописать запрет на доступ к панели администратора и конфиденциальным данным.
Неверно составленный файл испортит индексацию в поисковиках. Стоит неправильно указать директивы роботс для сайта, и из поисковой выдачи вылетит половина страниц и разделов, приносящих трафик. Составление правильного синтаксиса — еще одно требование при работе с robots.txt. Появление ошибки в командах и спецсимволах приводит к тому, что во время анализа и проверки ресурса робот не поймет ограничений и проиндексирует страницу, которую вы хотели закрыть. Или наоборот — закроется посещаемый раздел, и сайт лишится трафика. Мы уже писали о том, как повысить трафик за счет работы с релевантностью страницы.
Какие бывают директивы и как их настраивать
User-agent
Определяет, для каких поисковых алгоритмов составлен роботс. Эту команду указывают первой при создании файла. Как и остальные директивы User-agent составляется по шаблону. Вот правильный порядок — название директивы, двоеточие, пробел, значение команды. В случае с User-agent значением будет название поисковых роботов.
Примеры синтаксиса:

Disallow
Запрещает роботам индексировать указанные страницы и подразделы. Чтобы закрыть весь ресурс от поисковых алгоритмов, в значении команды поставьте символ «/». В данном примере запрет касается подраздела «page», который расположен следом за правильным URL-адресом сайта. Например, http://directive.ru/page.

Синтаксис директивы можно настраивать символом «*». Нужно поставить его перед «/» и прописать формат документов, которые необходимо запретить для индексации. Например, «doc» или «pdf». Все документы с этим форматом роботы будут игнорировать.
Allow
Разрешает доступ к страницам. Для этой команды актуальны все настройки Disallow. В этом примере мы запретили поисковым алгоритмам индексировать весь сайт с помощью Disallow, кроме разделов, которые начинаются с /page ( Allow).

Можно настраивать взаимодействие разрешающей и запрещающей директив с таким синтаксисом:

Доступ к страницам /blog закрыт, а подраздел /blog/page работы проиндексируют.
Sitemap
Указывает путь к XML-карте сайта. Если их несколько, для каждой новой используйте отдельную команду. О том, как настраивать карту сайта и почему она важна для SEO, читайте здесь.

Clean-param
Команда убирает лишние страницы, которые повторяют содержание индексируемых разделов. Clean-param очищает URL, удаляя ненужные метки, фильтры, информацию о сессиях и т.д. Возьмем такую страницу:
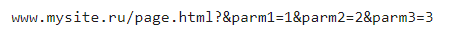
И настроим директиву:
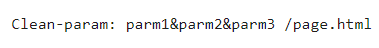
Роботы во время проверки уберут из индексации выбранный динамический URL для всех страниц /page.
Crawl-delay
Указывает алгоритмам Яндекса, сколько секунд нужно подождать перед загрузкой очередного раздела. Команда спасает ваш сервер от дополнительной нагрузки, когда роботы часто заходят на ресурс. Синтаксис самый простой:

Правильная настройка robots.txt
Можно использовать шаблоны, где указаны стандартные настройки без анализа особенностей вашего ресурса. Вслепую загружать такой файл на сайт не стоит — роботы могут криво проиндексировать его.
Настраивать robots.txt всегда лучше самостоятельно. Четко проверяйте, какие страницы нужно закрыть для индексирования, и не допускайте ошибок в командах. Синтаксис файла роботс устроен по простым и понятным законам — не нарушайте их, чтобы алгоритмы верно проиндексировали ваш ресурс.
Расскажем, как указать правильные настройки в чек-листе:
- Одна строка — одна директива. Проверка этого принципа — первая цель после того, как составлен роботс.
- Значение команды пишите в одной строчке.
- Составляйте их без точек с запятой, кавычек и заглавных букв.
- То же самое для меток слежения (*utm, *clid и т.д.).
- Настройка Host, Clean-param и Crawl-delay для Гугла производится в Google Search Console.
- Основное правило составления файла — никаких пустых строк. Они появляются только между директивами User-agent и между завершающей User-agent и Sitemap.
- Разрешите доступ ко всем файлам JS и CSS из системных папок. Необходимо для корректной индексации.
- Укажите в Allow известные форматы изображений (*.jpg, *.png и т.д.). Это перестраховка для того, чтобы страницу не проиндексировали без картинки.
- Аккуратно настраивайте доступ ко всем страницам со служебной информацией, секретными и персональными данными. Их лучше закрыть от роботов.
- Для Яндекса укажите корректный Host, следите за синтаксисом.
Как добавить robots.txt и где лежит файл
Роботс составляют в простой текстовой программе — блокноте. Анализ работы поисковых алгоритмов показал, что лучше собирать файл прямо там, а не в других редакторах. Блокнот поддерживает кодировку UTF-8, а некоторые программы работают с другими настройками. А их поисковики могут некорректно проиндексировать.
Обязательно нужно указать имя файла — robots.txt. Сохраняем его и размещаем строго в корневом каталоге сайта. Файл должен открываться, например, по адресу — http://www.directive.ru/robots.txt. Подраздел — http://www.directive.ru/blog/robots.txt — не подойдет, в этом случае роботы его не проиндексируют.
Настраивать роботс можно и после загрузки на сайт. Если допустили ошибку и заметили после анализа, ее легко поправить в файле.
Проверка синтаксиса
После размещения robots.txt в корневом каталоге стоит провести анализ настройки директив. Даже если вы не в первый раз составляете список команд для роботов, лучше воспользоваться проверкой файла на предмет ошибок. Правильный синтаксис — залог успешного индексирования. Например, одна ошибка в команде Host будет стоить вам трафика.
Для анализа используйте Вебмастеры Яндекса и Google. Нужно указать адрес ресурса и в пустое поле скопировать текст из роботса. Проверка займет пару секунд, и сервис сообщит о найденных ошибках.
Вывод
После проверки robots.txt работа с ним не завершена. Вносите изменения после появления новых страниц. Проводите анализ сайта, составляйте новые ограничения, настраивайте синтаксис и следите, чтобы роботы четко индексировали ресурс. После каждого изменения проводите проверку.
Услуги, которые будут вам интересны

А также поделитесь статьей с друзьями в соцсетях.



